


Introduction
After finishing my degree in Edinburgh, I have continued studying Deep Learning in my free time by participating in a study group at work, quickly looking through the material of an online course on Kadenze, trying out a bit of Reinforcement Learning.
I’ve always wanted to do tackle a more advanced computer vision problem with neural networks than CIFAR classification, with limited resources (no good GPU) and experience, I’ve decided that an iterative approach will work best. I’ve decided to start with Dogs vs Cats classification from Kaggle.
The Dataset
For this project, I used the cats and dog dataset containing 25,000 variable size images of cats and dogs. I have permanently split off 5000 to act as the validation set and used the remaining 20,000 as the training set.
Phase 1: Training on the GPU
I set up the dataset for training, trained the network on a GPU and set up a baseline for further runs to evaluate further runs
Goals
After graduating, I realized very quickly that even if I devised a sophisticated neural network and came across a decently sized dataset, I wouldn’t have anything to run it on. Therefore, with a fair bit of help from my dad, I have set up a deep learning environment on a server back home in Lithuania.
I have never trained on a GPU before, as my university only offered undergraduates CPUs. Therefore, as a start, my goals were:
- Use Keras to find how much it differs from TensorFlow.
- Prepare the dataset of cats and dogs for learning. Figure out how to store it correctly during training.
- Decide on the data augmentation to be used. Prepare and store augmented images or implement augmentation on the fly.
- Find a comfortable way of organizing a deep learning project, that works for me and would apply to projects in the future.
- Successfully run a training run on a GPU.
- Evaluate how efficiently GPU is being utilized.
- Establish a baseline validation accuracy measure for further runs.
- See if I can develop additional tools that could be reused in future projects.
Implementation
Getting to know the server
To start with, I got to know the server controls. Thanks to my dad, I could power on the server remotely and ssh into it. I could also log into a running Jupyter Notebook, allowing me to program remotely.
Data Input
After an unsuccessful attempt at using TFRecords for storing the images, I decided to just split the classes into folders and pass them to Keras. Some of it was done in Jupyter Notebook, and some with Bash. I’ve applied simple data augmentation, randomly horizontally flipping the images, shearing them by up to 20% and / or zooming by up to 20%. No other augmentation ratios were tested at this point.
Devising the Network
I’ve chosen to make the network fairly straightforward. Here’s the summary of it:
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 32768) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 4194432
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 129
=================================================================
Total params: 4,195,457
Trainable params: 4,195,457
Non-trainable params: 0
I found that using a batch size of 256 seems to be the highest multiple of 2 that doesn’t cause a memory error, so I stuck with it for now.
With the network ready, I have set the training to run for 2000 epochs, which took less than a day (I did not time it at this point).
Evaluating the GPU load
I’ve observed the GPU load every second by running the command nvidia-smi -l 1, right after starting the training.
Obstacles
Initially, the hardest obstacle was deciding how to encode the data. I believe that initially I was trying to pack all the images into a TFRecord object, but ultimately gave up on the idea due to difficulties in loading it afterwards in Keras.
Later, a large obstacle was a memory leak that was happening when attempting to run virtually any network. I would leave it for the night and find it crashed in the morning. I’ve set up a memory callback and observed that memory use only ever increases after each epoch. Ultimately, it was a fault in my Keras version and after half a day of digging through git issues, I’ve updated it, which solved it.
Results
Training Run
The training completed successfully and reached the following:
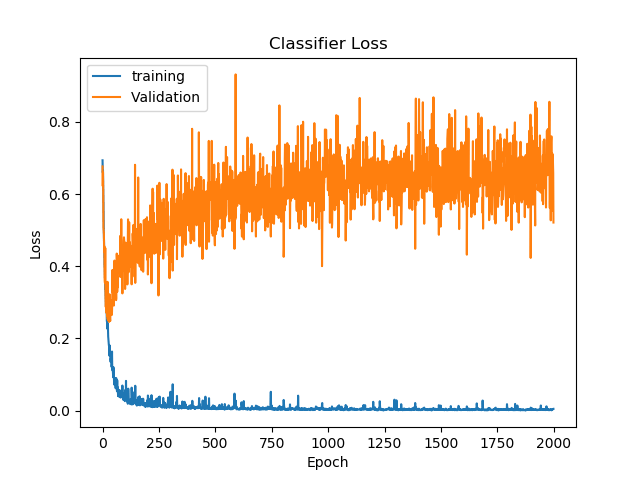
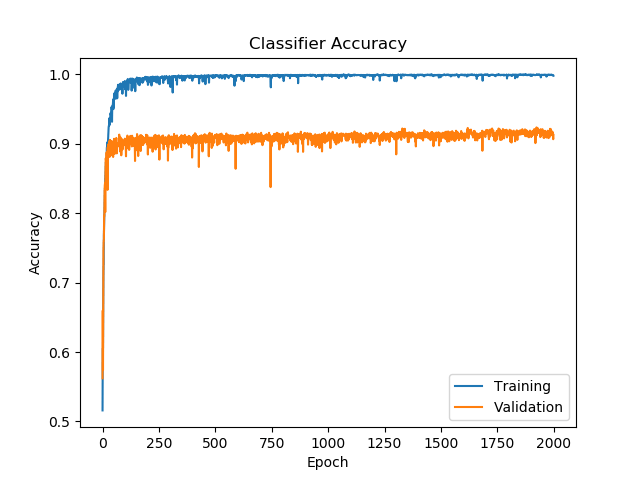
Highest validation accuracy: 0.8052, at epoch 287
Lowest validation loss: 0.4278, at epoch 82
Final validation accuracy: 0.7818
Final validation loss: 1.0482
The network overtrained significantly, with validation loss reaching its minimum at epoch 82 and started increasing from then on, as the training loss went ever close to zero. Meanwhile, from around epoch 82, the validation accuracy plateaued.
All results can be found on Gitlab
GPU Evaluation
I have immediately noticed that GPU is not being utilized very well. The usage would jump to ~90% for a second and then drop to 0% for 5-10 seconds. I believe that due to the model being fairly simple, it is computed very quickly, waiting on more data input. A more sophisticated model needs to be developed, that can be parallelized more efficiently, increasing the predictive power over the baseline and fully utilizing the GPU.
Phase 2: Full GPU Utilization
I devise a network that fully utilizes the GPU.
Goals
Now that I had the baseline, I had to implement a more complex network, that could be parallelized. It should:
- Have more predictive power.
- Bring the GPU utilization to at least 80%, and make it uniform, or at least more frequent.
I also wanted to continue to look at the following:
- Find a nicer way to structure the project.
- Create better tools for displaying the results. Find out which metrics to store.
- Store model checkpoints and other data that would allow to continue training in the future.
- Look for a better way of equalizing images or taking in varying size images.
Implementation
Data Exploration
To explore the size distribution of the images, I explored the data in Jupyter Notebook. I plotted histograms for the heights and widths of the images from the dataset. I have also carried out a small literature review in regarding the network architecture, and a better way to scale the images before presenting them to the input pipeline.
Project Structure
Here, I found a brilliant solution. Cookie Cutter Data Science had the exact solution I was looking for. Taking a very similar project structure to what they proposed, I laid out my project in a way that neatly separates all the moving parts. At the time, this helped considerately, as I understood that I need to move my model definitions and training away from Jupyte Notebooks.
Training Run
After some deliberation and a literature review, I have decided to adopt the following network architecture:
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 100) 2800
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 100) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 200) 180200
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 16, 16, 200) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 300) 540300
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 8, 8, 300) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 8, 8, 400) 1080400
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 4, 4, 400) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 4, 4, 500) 1800500
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 2, 2, 500) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 2, 2, 600) 2700600
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 1, 1, 600) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 600) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 601
=================================================================
Total params: 6,305,401
Trainable params: 6,305,401
Non-trainable params: 0
This had the advantage of higher predictive power due to more hidden layers. The algorithm used a batch size of 512 and ran for 2000 epochs. This took more than 21 hours.
GPU Utilization
I have run GPU utilization queries after starting the training, for a few minutes:
timeout 86400 nvidia-smi --query-gpu=timestamp,name,pci.bus_id,driver_version,pstate,pcie.link.gen.max,pcie.link.gen.current,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv -l 1 > "gpu_load - `date +"%Y-%m-%d %H-%M-%S"`.csv"
Results
Ultimately, this phase was a complete success. I have both trained the network, fully utilized the GPU, found very nice project layout guidelines, created lots of useful tools for model metric tracking, and even found some unexpected outliers.
Here are my notes for the next step.
Data Exploration
I didn’t expect to find outliers in the dataset. However, when plotting top 10 most skewed photos by the ratio abs(x_dimension - y_dimention), I have seen that at least three images did not contain cats or dogs and were definitely outliers. Luckily, all of these were in the training set and could be removed easily. Aside from that, I have decided that the simple scaling of images regardless of aspect ration will work good enough for now. I have chosen a better image size - 64x64.
Training Run
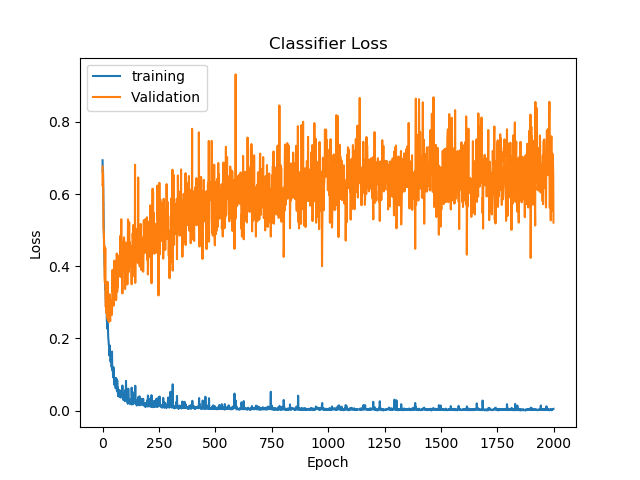
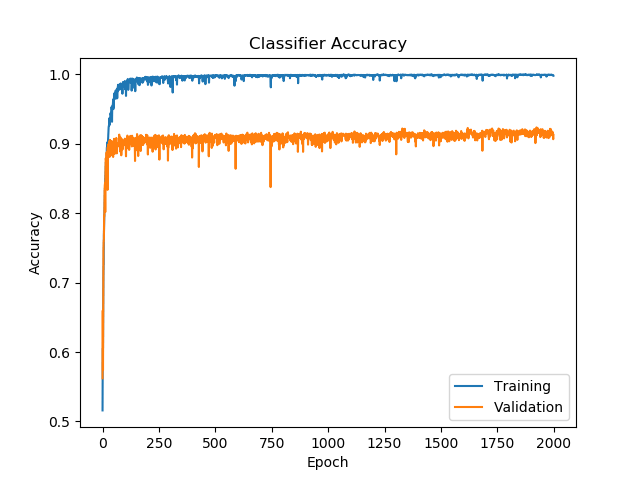
With just a ~50% increase in the parameter count, the resulting validation accuracy has improved by almost 12%!
Highest validation accuracy: 0.9236, at epoch 1924
Lowest validation loss: 0.2458, at epoch 29
Final validation accuracy: 0.9128
Final validation loss: 0.5212
This shows that removal of dropout was not a good idea, or that I should have used other methods to prevent overtraining.
All results can be found on Gitlab
GPU Utilization
There is nothing much to say here except that my GPU was finally fully utilized. There may be a better way to understand it, in addition to the utilization values, but for now, I am very much satisfied with the results.
Tools and Other Discoveries
After moving away from Notebooks I started using PyCharm to develop the code. I found that I can mount the working directory with sshfs, allowing me to edit the code directly, at a cost of saving taking 5 seconds or so, instead of being instantaneous.
Other tools were added:
- CSV logger for tracking training results of every epoch.
- Model summary generator
- Best-epoch model saving
- Numerous functions for tracking results of a Keras model performance.
Lastly, I found Mendeley - an amazing desktop app for annotating research papers.
Phase 3: Optimizing for longer runs
(In Progress) I attempt to grab some low hanging fruit by optimizing my network for longer runs and, hopefully, decreasing overtraining
Goals
The next step after a successful CNN run is to reduce overtraining. Possibly, if I spread out the training over a longer period of time, I could achieve better results. Therefore, my goals for now are:
- Reduce the learning rate. Experiment with learning rate annealing.
- Reintroduce dropout
- Load previous models and submit results to Kaggle.
Afterthoughts and Further Plans
Among the utilities that are still needed, It would be useful to have a way to shut down the server after a training run finishes.
Also, I need to make a submission to Kaggle, for once. I have the data files and functions to generate it, but haven’t come to that yet.
Next, the network needs to be improved so that higher accuracies could be achieved. Currently, overtraining can be seen very well, and that needs to change. I might also investigate transfer learning or go towards image segmentation.