In 2013 Andrej Karpathy provided a description of Policy Gradient learning for Atari Pong in his blog. I have studied the approach, coded up my version of it in TensorFlow and attempted to apply it to the Cart Pole problem in AI Gym, with little success. The moving average of the reward just fluctuated back and forth in a regular, sine wave-like patten, not making any gains beyond a certain point, way below the goal. From this standpoint, this project serves the purpose of letting me see a working reinforcement learning project in action. I want to see the reward change, I want to observe the gradual convergence or the lack of it, I want to understand how long it will take to converge with the basic methods. Therefore, I have decided to perform a training run of Karpathy’s Policy Gradient training to observe the results it gives.
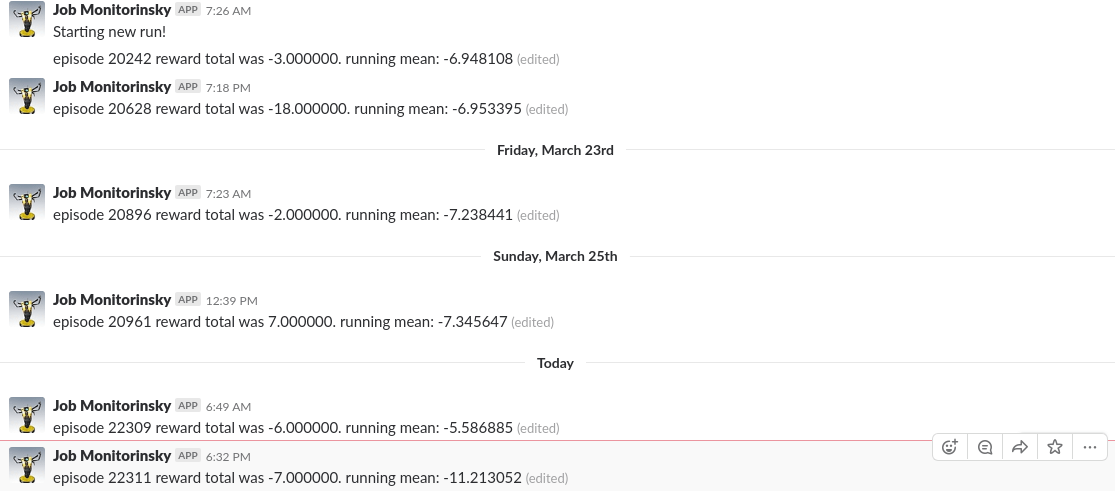
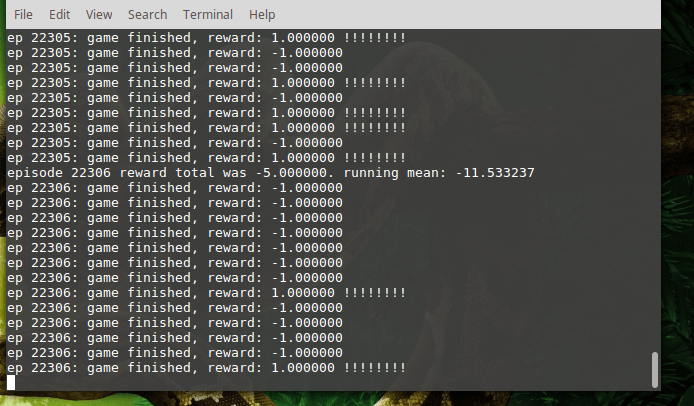
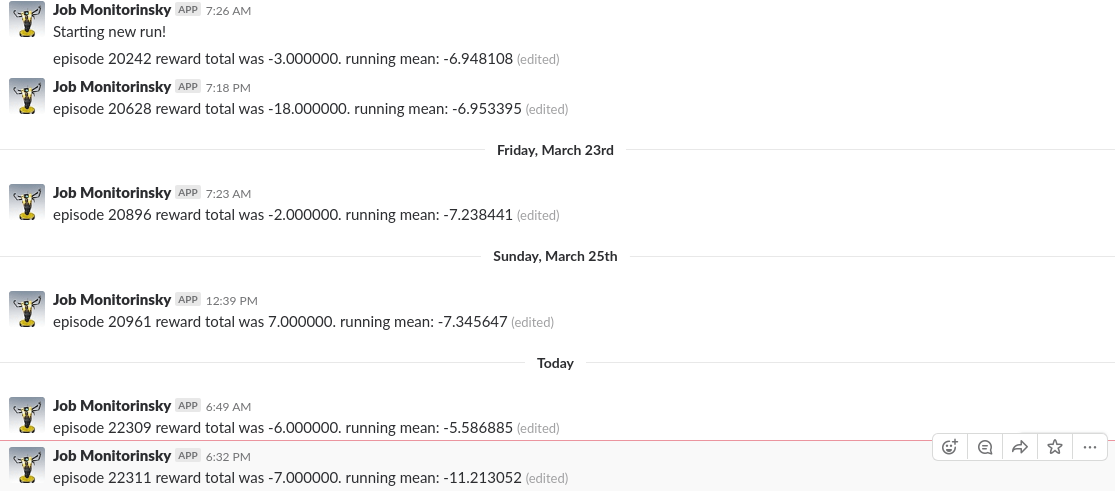
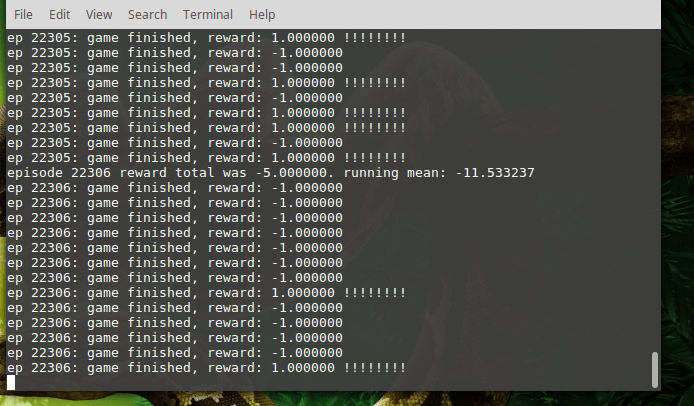
I ran the training code irregularly on my laptop, leaving it to train while I was at work. The training was run for approximately 16 days, reaching epoch 27065. Each epoch consists of one game, which is played until 21 points are scored, cumulatively, by both sides. Each point for the agent increases its reward by 1.0 and each point scored by the default AI decreases the agent’s reward by 1.0. After training for the given duration, the agent obtains an average of -1.96 points (running average over approximately 1500 games). This means that the agent became almost as good as the default AI.
Now that I have completed this project, I am planning to go back to some of my earlier Deep Learning projects - Cat / Dog recognition with Convolutional Neural Networks or Cart Pole learning with Policy Gradients.
Furthermore, we have a deep learning reading group at work, for which we will be doing group projects. Karpathy’s Atari learning was used as the first starting example from which we are planning to build up out knowledge. There are multiple paths to pursue from this point and the work done here will hopefully help us decide on the next steps.
Original post in Andrej Karpathy blog